第十章 上下文对象
严格地说,上下文(Context)并不是一类对象,它是一个概念上的数据集合, 而实现上就是一个字典的数据结构。但是它却在数据传递过程中有着非常重要的作用。本章将详细介绍上下文的概念及其使用方法.
前台使用场景
1. 传递默认值
我们可以在窗口动作(ir.actions.act_window)对象中定义上下文, 然后设置将要打开的页面的默认值:
{'default_customer':1,'default_is_company': True}
这个特性,我们在之前搜索窗口一节中提到过, 系统会自动分割default_后的文本, 匹配对应的过滤条件.
另外, 也可以我们也可以在视图中针对x2many的字段中定义上下文,控制其打开视图的默认值:
<field name="analytic_account_id" context="{'default_partner_id':partner_invoice_id,
'default_name':name}" />
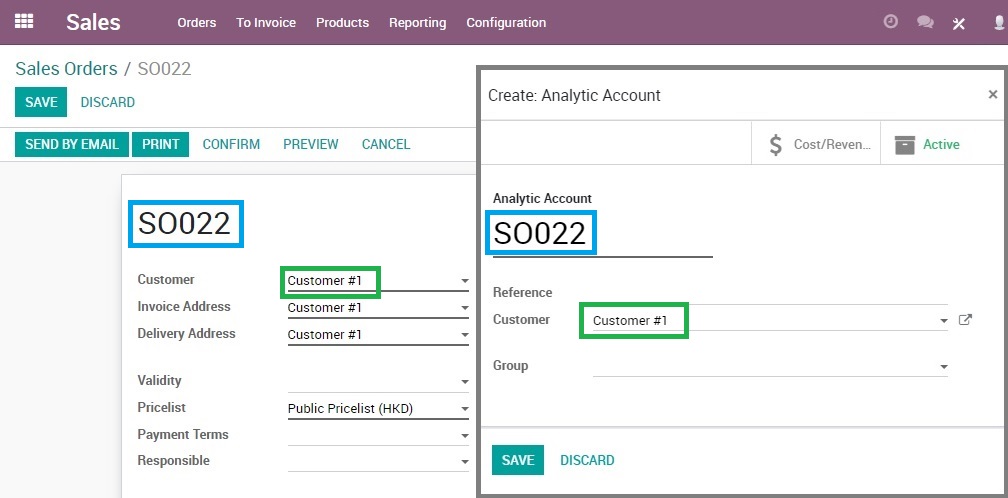
对于x2many字段来说, context中的默认值,在创建过程中也会被设置为创建对象的默认值.
2. 设置过滤值
上下文当然也可以应用在控制面板视图(search view)的过滤器中,例如"客户"菜单,根据我们之前的了解,我们知道"客户"其实只是合作伙伴的子集,我们在点击"客户菜单"时,其实正是因为上下文对象起作用,让我们只看到了客户.
{'search_default_customer': 1}

odoo中的过滤大致可以分为硬过滤和软过滤两种, 硬过滤是指那些用户无法绕过去的过滤,例如记录规则和域.而软过滤则是指用户可以自行去掉的过滤,比如这里的搜索过滤.
以上特性,也可以用在字段中:
<field string="Customer" name="partner_id" context="{'search_default_customer':1}" />
3. 分组设置
上下文对象也可以放在分组设置中:
{'group_by': ['date_invoice:month', 'user_id']}
展开:
{'expand': 1}
4. 设置语言
正常情况下,一旦用户选择了语言, 系统将会使用用户选择的语言显示所有的内容. 但是如果字段的上下文中设置了语言,就可以实现在特定的地方让用户检查另外一种语言的翻译, 而不用再去切换整体的语言环境.
{'lang': 'fr_FR'}
xml示例:
<xpath expr="//field[@name='order_line']" position="attributes">
<attribute name="context">{'lang': 'fr_FR'}</attribute>
</xpath>
或
<page string="Order Lines" name="order_lines">
<field name="order_line"
widget="section_and_note_one2many"
mode="tree,kanban"
context="{'lang': 'fr_FR'}">
后台使用场景
我们在后台代码中使用上下文对象通常使用的都是环境变量中的上下文对象.
self.env.context.get("xxx",None)
也可以直接使用self._context, 这两者是等效的.(原理参见模型一章)
1. 环境变量中的上下文对象
上下文在环境变量的创建过程中就被赋值了,不过传入的上下文被frozendict化了,因此环境变量中的上下文是不可变的,不可以通过赋值的方式试图去改变它的值。
def __new__(cls, cr, uid, context, su=False):
...
# otherwise create environment, and add it in the set
self = object.__new__(cls)
args = (cr, uid, frozendict(context), su)
self.cr, self.uid, self.context, self.su = self.args = args
...
从代码中我们可以看出,self.context是一个不可变的字典,即我们不能通过赋值的方式改变它的值。那么,如果我们希望在某些条件上切换用户的上下文变量,该如何做呢?
这个时候,就到with_context方法上场的时候了。
既然Environment对象的context上下文不能被改变,那么我们就把整个Environment对象换掉好了。我们来看with_context方法是怎么做的:
def with_context(self, *args, **kwargs):
""" with_context([context][, **overrides]) -> records
Returns a new version of this recordset attached to an extended
context.
The extended context is either the provided ``context`` in which
``overrides`` are merged or the *current* context in which
``overrides`` are merged e.g.::
# current context is {'key1': True}
r2 = records.with_context({}, key2=True)
# -> r2._context is {'key2': True}
r2 = records.with_context(key2=True)
# -> r2._context is {'key1': True, 'key2': True}
.. note:
The returned recordset has the same prefetch object as ``self``.
"""
if (args and 'force_company' in args[0]) or 'force_company' in kwargs:
_logger.warning(
"Context key 'force_company' is no longer supported. "
"Use with_company(company) instead.",
stack_info=True,
)
if (args and 'company' in args[0]) or 'company' in kwargs:
_logger.warning(
"Context key 'company' is not recommended, because "
"of its special meaning in @depends_context.",
stack_info=True,
)
context = dict(args[0] if args else self._context, **kwargs)
if 'allowed_company_ids' not in context and 'allowed_company_ids' in self._context:
# Force 'allowed_company_ids' to be kept when context is overridden
# without 'allowed_company_ids'
context['allowed_company_ids'] = self._context['allowed_company_ids']
return self.with_env(self.env(context=context))
从中可以看到,forece_company在当前版本(14.0)中已经被弃用了。with_context内部调用了with_env方法返回了一个使用了新的Environment对象的记录。而with_env又是何方神圣?
def with_env(self, env):
"""Return a new version of this recordset attached to the provided environment.
:param env:
:type env: :class:`~odoo.api.Environment`
.. warning::
The new environment will not benefit from the current
environment's data cache, so later data access may incur extra
delays while re-fetching from the database.
The returned recordset has the same prefetch object as ``self``.
"""
return self._browse(env, self._ids, self._prefetch_ids)
这就清楚了,with_env内部调用了低阶的_browse方法获取一条新的记录,而_browse方法第一个参数就是env变量,当我们传入了新的env对象和旧的记录id时,就完成了对之前记录的context上下文的替换。
2.搜索归档的记录
第一章提到过的search方法,有一个默认的行为,就是只搜索active值为True的记录。有些时候,我们希望能够搜索到active为False的记录,只在domain中添加 active = False 是不够的。正确的写法是利用with_context:
product_obj.with_context(active_test=False).search([
('default_code', '=', data["Cpcode"]),
('barcode', '=', data["barcode"]), ('active', '=', False)], limit=1)
3. 强制使用某公司
多公司环境下,如果我们想要代码在某单一公司的环境下运行,可以使用下面的方法:
self.sudo().with_context(force_company=company_id)
force_company意味着强制使本行代码在company_id公司下运行,比较典型的使用场景是,查询某个公司的库存。如果当前用户拥有多个公司,默认情况下返回的是所有公司库存的总和。
4. 多公司环境下的使用
当前用户的公司: self.env.user.company_id 当前环境下的公司: self.env.company (注意这里是company 而不是company_id)
高级技巧
1. 向导下的Many2one字段的过滤
使用Env来解决动态domain的问题是一个非常有效的方法。由于odoo系统本身功能的限制,我们并不能很容易地在视图中动态设置domain的值,这对于某些场景下显得非常尴尬,例如,笔者的一个客户项目中,需要在向导中对产品进行限定,限定的值又是另外一个对象的One2many中的产品ID列表,由于Odoo并没有一个列表类型的字段,因此我们不能使用关联字段的方式来进行过滤,这就成了一个很棘手的问题。
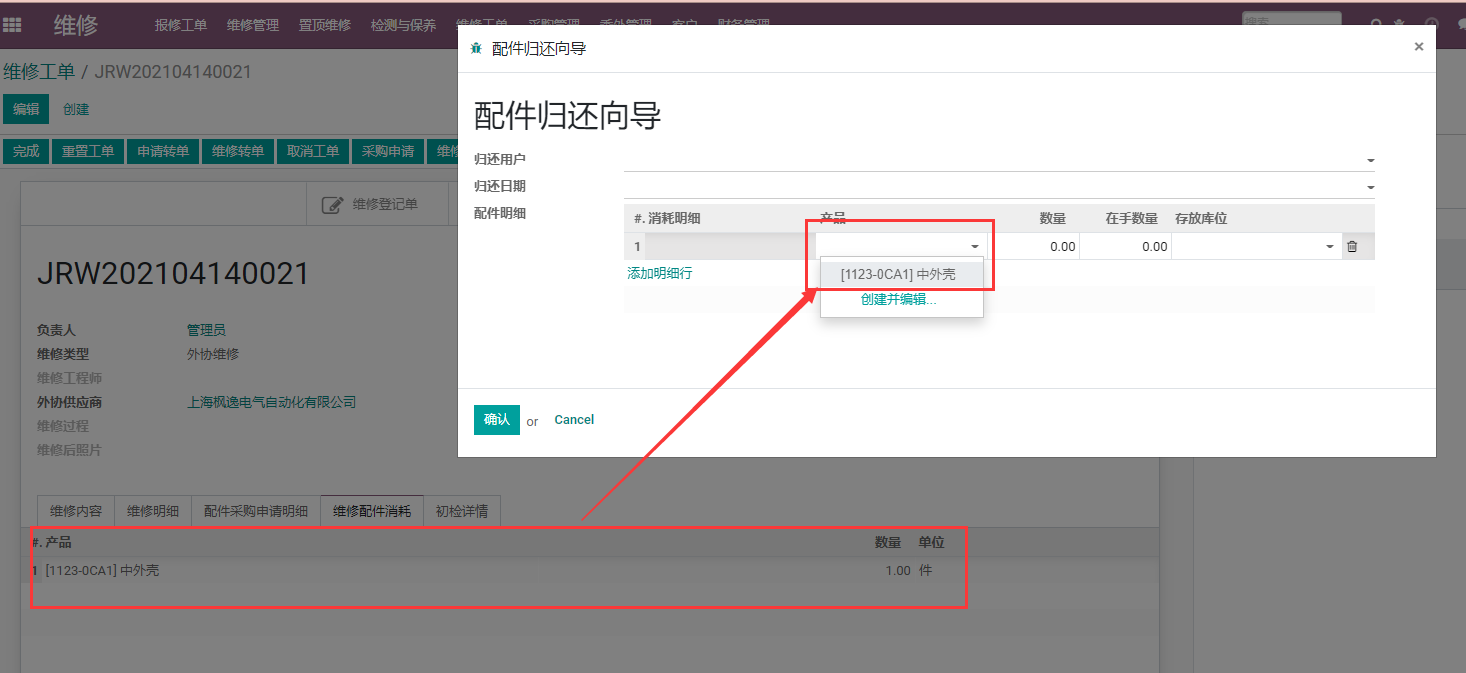
这时候,我们可以通过env来曲线地完成这个任务,首先我们在product_id字段地属性context中添加当前环境地模型和id:
<tree editable="bottom">
<field name="product_id" context="{'active_id':active_id,'active_model':active_model}"/>
<field name="quantity"/>
<field name="inventory_qty"/>
<field name="location_id"/>
</tree>
然后我们在product_id的多对一对象product.product的name_search方法中对active_model进行判断,如果是符合我们的要求的模型,就使用我们的自定义逻辑:
_inherit = "product.product"
@api.model
def name_search(self, name, args, operator, limit):
model = self.env.context.get("active_model")
if model == "juhui.repair.workorder":
active_id = self.env.context.get("active_id")
workorder = self.env[model].browse(active_id)
ids = [line.product_id.id for line in workorder.consume_lines]
args = [('id','in',ids)]
return super(product_product, self).name_search(
name, args, operator, limit)
这样 我们就完美地实现了向导中Many2one字段的过滤。
说明
- OdooTricks网站对本章内容亦有贡献.